关于机器学习的一些思考
这篇文章本来是写在上一篇的结尾的,因为实在是太长了,单独拆分了出来。
我们再讨论一下transformer模型的能力极限吧,chatGPT刚出来的时候,很多人都感觉到非常的惊艳,似乎聊天机器人很可能实现类似人类水平的智能,整个世界都似乎被震撼到了,引起了AI行业的狂热。
然而这只是表象,我们这里仔细的观察讨论一下transformer最核心的原理和技术,然后再对他的能力极限的做出一个判断和预测。
依照技术的进化路径,我们先从词向量和RNN来说起。
什么是词向量或者说词嵌入呢?它的英文叫word embedding,原理就是用若干个数字来表示一个字或者词。比如道这个字,我们用256个数字来表示它,比如(0.2,0.6,0.8,…..,0.7),为什么要这样干呢?因为用一串数字来表示它的话,就可以表达很多细微的概念和意思,而且这些数字可以进行一些运算操作,比如king在英语里表示国王,women表示女人,man表示男人,那么我们进行一些数学运算,比如king减去man再加上women会得到什么结果呢?没错,跟我们的直觉是一样的,得到的结果就是queen,也就是女王。这是nlp领域里边非常著名的一个例子,一般讲词向量都会用这个来举例。
实际上词向量的核心思想就在于,每一个词都用若干个更基础的原始概念来表示,我们看到前面表示道字的256个数字,其实就是底层的256个概念每一个占的权重。
词向量是lstm还有transformer的基础,他们的输入都是先把每个字或者单词映射成词向量的数字序列。也就是模型里面的word embedding层。
最早nlp领域出现的是gru和lstm这些循环神经网络模型,它们是为了解决机器翻译问题而提出的。
lstm最大的问题在于每次输入都是单独的,虽然记忆单元能够捕获一定的前面输入过字的语义,但它很难完全的理解获取整个上下文关系。
举个例子,比如‘道’这个字,如果只是简单的进行词嵌入,比如用256个数字来表示它的意义,那么它的意义到底是什么呢?他有道路的意思,也有说话的意思,还有方法的意思。我们用一个简单的词嵌入向量是无法表达它的,看下面几句话:
大道至简
前面有一条小道。
他说道:“我们应该回去。”
在这几句话里,每一个道字都有不同的含义,如果还想再复杂一点儿,我们可以看下这句话:
道可道,非常道。
对于我们正常的人来说,给一个词或者字问是什么意思,我们怎么回答呢?很可能我们会说它有好几个意思,我无法确定他到底是哪一个,但是如果你告诉我一个句子,包含了上下文,那我就能跟你说出来他确切的含义。
这就是lstm这种模型最大的问题,他的词嵌入是固定的,每次独立的输出很难获得完整的上下文,实际上也有方式来补救。ELMo模型,就是使用两个双向lstm获取动态的上下文信息,对不同语句中出现的相同词语会输出不同的embedding。
而且在lstm的翻译模型中,只有把编码器最终的输出跟解码器连接起来,这样就失去了很多上下文关系,attention机制就是在这种情况下提出来。可以通过在前面的那篇文章里的例子对比就能发现,加入Attention机制之后的效果改进实在是太大了。
attention机制是如此的重要,以至于一些人专门儿基于它设计了一种架构,并发表了一篇叫做attention is all you need的论文,提出的模型就是Transformer,他们当初主要是为了解决机器翻译问题,恐怕也没有想到这个模型会对整个nlp领域造成如此巨大的影响。前段时间的GTC大会,老黄还专门邀请了这篇论文的几个作者到一起进行对话讨论,并表示:“整个行业都对你们的这一成就心怀感激。”
我相信老黄这句话是发自肺腑的,本来是一家卖游戏显卡的公司,靠这个模型摇身一变成为一家人工智能公司,过去一块儿显卡能卖1万块已经是顶天了,现在一块儿同样架构核心的加速卡直接就能卖到一二十万,简直是赚翻天,感觉现在老黄都不怎么关注游戏玩家了,很多人打游戏还在用好几年前的1650。
我们下边就研究一下Transformer的attention机制,仔细的看一下,对于输入的词向量序列,它是如何变换的。
假设输入的维度是n*d,首先把输入经过不同的线性层变换成三个不同的序列,分别是query,key和value,也就是qkv,然后对q乘以k的反置,得到一个n乘n的矩阵,然后用这个矩阵来乘以v得到输出,我们要注意一下这时候输出维度刚好又变成了n*d,折腾了一圈,输入的形状结构没有任何变化,但是每一个词向量的值却发生了变化,实际上就是这个过程,根据上下文相关性把每一个词变换成它应有的意思了,所以这个模型叫做transformer,还是非常形象的。
事实上transformer是把词向量拆成几个小块单独计算attention最后综合到一起,最终的矩阵形状是一样的,叫做MultiHead Attention。这么做主要是为了更好地把握每一个词下面单独的若干概念之间的联系,可以更精准地把控语义。
事实上这个n乘n的矩阵,就是代表了句子里的每一个词和词之间相关性的联系,我们看一下下面这张图。(我懒得自己画图了,这张图片是直接网上找的,要是有侵权请联系我删掉。)
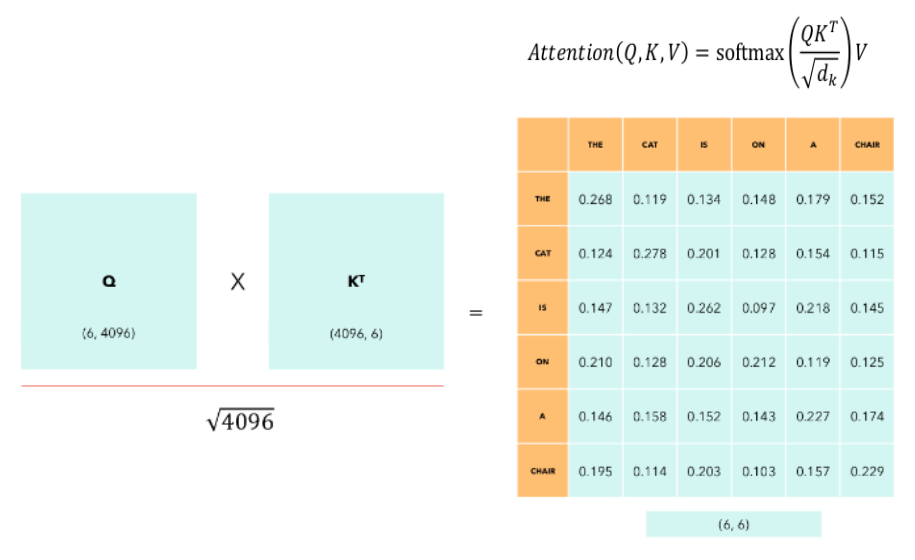
上面最后那个矩阵显示了the cat is on a chair这句话每个单词之间的对应联系权重。经过这个权重变换后的句子序列的每一个词向量,都是变换后根据上下文相关性生成,包含了具体确定的意义的概念组合。
所以说,Transformer的attention机制真的非常重要,那篇论文的题目叫attention is all you need是非常贴切的。
Transformer模型解决了这些上下文相关的语义,而且不基于时序,相比比lstm更易于训练和规模化扩展,直接风靡了整个业界。当初bert一经推出就在各大榜单上显示出非常优越的效果,更不用说后面大家都知道的chatGPT了,现在nlp领域已经基本没什么人去关心lstm了。
从论文发表至今,六七年已经过去了,transformer仍然还是当之无愧的业界的统治者,我们看到的进步只不过是不停的搞更大的参数,更多的训练数据而已。当然也有架构上的一些优化改进,但这些都是边边角角了,并没有本质上整个结构性的改变。
实际上gpt并没有使用整个Transformer,而只是用了它的decoder解码器部分,为什么这样就工作的很好呢?很简单,这再一次说明了attention机制的重要性,解码器也不过是一些这样attention变换的堆叠,之所以有编码器,因为tranfromer最初提出的动机是想解决机器翻译的问题。实际上只是单独的简单的堆叠解码器就足够了,每一次变化都能获得上下文相关的语义的理解。只要训练数据足够大,我们仅仅依赖于解码器就能实现翻译程序,比如把现代文放在前面,中间加一个特殊的标记来表示翻译符号,后边跟着文言文的输出,用大量这样的数据来训练就可以了。
对于大模型来说,当他训练的数据足够的多,翻译文言文甚至都可以直接当做聊天机器人的提问,比如在提示窗口里输入,把xxxxx这句话翻译成文言文,它就会给出相应的翻译输出。
所以我们为什么要花力气训练单独的翻译程序呢?直接训练一个特别优秀的大模型就能解决所有这些问题,根本不需要再单独的折腾了。
然而对于只是简单的推理过程,现在大模型都需要大量的算力,而且他还没并没有对这些翻译数据进行优化训练,所以训练专门特殊应用模型还是有一定价值和意义的。但是随着时间的推移,未来谁说的了呢?可能一二十年后算力这些都不是太大问题的话,我们的翻译程序可能也有很大的改进和不同。
我们再展望一下未来。Transformer统治了这么多年,是终极的模型吗?在很多表现上它都能给出足够好的结果,以至于让很多人觉得它似乎可能有一些智能的感觉。
然而直觉是并不可靠的,我们看看这个模型本身,有很多问题它都是解决不了。
第一个是没有动态的存储。对于我们每一个思考的人类来说,如果我们告诉听到一件事,就会把这件事情给记在大脑里,显然transformer模型并不拥有这些记忆。聊天机器人之所以能感觉到上下文,那是因为在回答下一次输入前,他把之前聊天框里之前所有的输入再重新跟新输入加在一起当做新一次的输入,这就给了我们以好像有上下文的假象,然而这都是trick。
而且整个attention机制加上一些其他的线性变换还有残值连接和激活函数,所有这一切如果从数学角度来看,都只是一个个简单函数方程进行不停的嵌套,最终得到一个足够复杂的方程或者函数,这个函数可能有几亿几百亿个参数,然而它的本质只是一个函数映射或者方程,训练的过程就是拟合这些参数的过程。这个方程本身我们说它就有智能吗?
显然不是。
不过我们下结论也不要过于笃定,很多东西都不好说。我们可以对这个方程加一些简单的其他操作,从我的直觉上来看,似乎是有可能实现一定的类似人类的认知和智能的。
首先是词向量,说实话,当我第一次接触词向量的时候,确实有眼前一亮的感觉。他解决了很多之前nlp领域头疼的问题。但是词向量本身是固定的,只是用一组数字来描述一个概念。这些基础的每一个数字是什么呢?也许是这些概念里边更基础的概念,但词向量的长度决定了这些基本概念就是这么多,而且是固定的。
我们人类大脑认知的情况并不是这样的,对于一个概念来说,他可能包含若干个子概念,而这些子概念可能每一个又包含另外的一些子概念。最重要的机制是,这些子概念是相互连接的,可能包含有各种各样的联系,概念与概念之间是一个树状或者是网状的结构,词向量只是一个固定的若干个概念的组合,这跟我们人脑的认知结构差别还是非常大的。
而transformer无论怎样变换上层的上下文语义结构,它的认知的基础概念就是词向量的维度这么多,而且这些基础概念都是独立的互不干涉的,所以他不太可能达到人类的认知水平。
除此之外还有一个就是,我们除了本身包含的这些概念之外,还能对这些概念进行思考总结,生成新的概念,产生概念与概念之间的联系。而transformer训练完了就是训练完了,他并没有新概念产生的机制,也就是说没有人类思考的过程。
况且对他来说一个概念是什么呢?对他来说只有词向量每一个基础的元概念,以及上层的这些概念组合形成的新的概念,当足够多的大量的数据来对应的时候,他似乎让我们觉得能理解很多我们人类所谓的一些概念,也许吧,如果他的参数足够多,那么可能能覆盖我们已知的一些概念和这些概念之间的联系,当参数越大,我们给他的数据也就是说这些概念之间的结构联系越多,他表现出来的效果看起来就会越好。
但是真正的人类智力的核心呢?显然他并不具备。人类真正的智力的核心是对这些已知的概念进行总结推理归纳,进而生成新的概念,或者把若干这些概念整理成几个精简的概念,这就是我们人类思考学习的过程。
所以说我们想要实现真正类人的智能的话,Transformer模型是不够的。我们一定要提出一个新的模型,这个模型能以我们思考的概念为基本元素,然后能动态的对概念进行归纳总结更新,而且还能生成新的概念结构。
整个训练的过程也要改,对于我们现有的大模型来说,训练好了参数就是固定下来了不会再改变了,但真的人类的认知过程并不是这样的,它是一个动态的过程,平时每天的对话,每天的看到听到的事物本身就是一个学习的过程,大脑也无时无刻也不停地对这些概念进行总结归纳。所以我们不能简单的直接给数据训练一种方式,它的使用过程中的输入都是一次新的认知或者训练过程,甚至每次推理的过程也要对已有概念进行总结提炼归纳,也就是说我们要引入一个思考的过程。
这样我们就把训练数据当成外部输入,输入之后这些数据在模型内部先存起来。包括其他后续的每次输入都是一样。另外我们在内部单独拆分出来一个过程,姑且把它称之为思考的过程吧,这个思考的过程就是对这些数据进行审视,建立内部概念连接的过程。
所以假设需要建立一个新的类人智能模型的话,并不是仅仅使用简单的训练来概括所有的学习过程。而是把整个训练过程拆分为输入,认知思考,和输出几个部分。每次输入都能引发内部的认知思考。没有输入的时候,模型本身也可以进行认知思考。
这个所谓的认知思考其实就是内部进行一个训练学习的过程,也就是前面说的对这些概念进行总结归纳或这生成新概念的一个过程。
我们再看一下transformer,如果从本身结构来看的话,他缺的另外一个东西就是动态的存储。就像我们前面说的,它并没有聊天的上下文,需要把所有历史的输入跟新的输入连在一起当成新的输入,才能产生上下文的相关性。
但是我们刚才讨论的改进的新模型就不存在这个问题,对于已有概念进行总结归纳产生新概念的过程,其实就是生成新的存储。
所以说这个新的存储在我们的类人智能模型中怎么来表示呢?
一种方式是我们想办法怎么动态的扩展这个词向量,另一种办法是直接用一种新的架构或者模块。
这个具体怎么实现我还没有想清楚,当然如果真的想清楚了,那就是革命性的一种改进变革了。它肯定没有那么简单,或者说它很简单,只是我们还没有想到。不过毕竟现在这个行业全世界的聪明人都在一起想方设法改进,或者说尝试解决方案。未来谁又说的了呢,说不定有很大几率被我们找出来这种东西。
如果真的能找到这样一种架构的话,那我们确实才需要开始真的去担心,人类的高阶思维是否会被机器取代。然后这里边还有一些更复杂的哲学问题等着我们,它能产生出来自我意识吗?
至少目前看来我们需要走的路还有很远很远,这些都是杞人忧天了。
好了,讨论完这些技术性概念性的东西,我们再看一下应用方面。
说实话,现在大模型确实存在一定的泡沫。很多公司的估值都高的不太正常。至少在我看来他们实在是很难盈利。聊天机器人实际应用价值并不是太广泛,也许客服之类的它能解放一些人工,一些公司也愿意为他进行付费,但这个市场并不是特别大,要是想撑起来类似于openai这些公司千亿美元的市值,还是远远不够。
但另一方面,深度学习相关的技术是一个巨大的市场,我们不能简单的局限于大模型聊天机器人。比如现在另一个火热的扩散模型生成图片的,在各种艺术创作以及游戏当中其实是可以真的产生一些生产价值的,虽然目前还早吧,但随着不停的迭代改进,未来应用场景还是很广泛的。
另外就是在各行各业当中的应用了,特别是模式识别或者图像识别。比超市里对水果蔬菜进行打秤,对于人来说这其实是一个很累的过程,要仔细的去看是什么水果,然后选择相应的品类打出来价格贴上去。我前段时间就见过一种能动态识别水果的秤,当时我把水果放上去,它自动显示出来砂糖橘和蜜橘两种选项,这样打秤的员工只要简单的在里边选出来确定具体哪一种就可以了,可以大大减轻他们的工作量。这种东西虽然看起来不是很起眼,但却是一种实实在在的应用场景,产生了一个实实在在的商品。而且全世界那么多超市,需要的这种秤的数量其实也不算少,未必就比那些火热的聊天机器人的利润水平低。
类似的应用场景其实多了去了,这就是我们为什么提出来要进行人工智能+类似的概念,各行各业都有很多可以相结合的,特别是模式识别和图形图像相关的应用,可以解决或者减轻很多工作量,这是实打实的技术进步和改善。
再比如说yolo算法,它的作者后来宣布退出了开发,他自己说是因为这项技术被大量的使用在军事和隐私窥探等相关的领域,他不想做恶。先不讨论具体的价值观念吧,其实yolo算法本身是很实用的,技术无所谓好坏,只是看人们怎么使用它了。这算是另外一个话题了吧,我们先不在这里讨论了。
所以说深入学习相关的这些技术,即便是现在投资界存在一定的泡沫,技术本身也是实实在在的进步,不然美国也不会闲着没事儿来限制我们了。这些技术跟那些所谓的区块链元宇宙纯粹炒概念不一样,即便是泡沫也是投资于人类的技术研发,推动科技进步。更何况这些钱大部分都是市场上的自由资本,大家愿意搞泡沫,烧钱推动本来可能是科研相关领域的东西,来共同实现人类的技术进步,也不是什么坏事。
另外一个就是美国对我们的限制了,说实话算力上的限制确实挺让人烦的,但长远来看,十年二十年的维度上来讲的话,顶多也就是一时的阻挡,改变不了大势。况且对大部分真正有价值实用的那些模式识别和图形图像相关领域来说,对算力的要求并不是特别的强烈,这反而是一件好事。追求大模型,把大量的算力花在这上面,引领技术的进步,也许能得到一些很激动人心的结果,但实用价值并不高。
况且现在技术架构上大家都没有什么新的突破,算力不足如果能迫使我们想方设法去研究新的模型或者架构,也未必是件坏事。另外要是能促使国内厂商在硬件和芯片方面的进步那就更好了。
最后讨论一下国内的现状,很多人应该都能感觉的到,我们并不能算是技术的引领者,仔细观察一下可以发现,很多创新的思想和技术还是都发生在国外。我们刚刚开始发展起来,目前还是追随者的位置。但我们也可以发现其实很多人工智能领域重要的研究者都是华人,为什么他们在国内就没有能做出很好的成绩到了国外却表现这么好呢?
这个问题很复杂了,我们应该看到欧美在引领人类技术进步方面已经积攒了好几百年了,吸引了全世界大量的优秀人才。他们的大学相对的更有底蕴一些,而且他们一直传承下来的科研以及交流合作沟通的整个理念体系都是需要大量的积累的。另外一个就是文化层面的或者说思想层面的,对于创新的一些无形中的整个氛围环境,这些都是他们几百年积累下来,在文化当中无意识的传承的,可能我们的汉语文化圈很难觉察得到。对于受过大量教育和良好训练的华人来说,到了这个环境会不由自主的被他的文化给带进去,形成正向的激励。
对此我们并没有必要去妄自菲薄,也没有必要操之过急,随着时间的发展都会慢慢地改善。其实我们现在最需要适应的是要逐渐的从追随者的心态,变为技术引领者的心态,只有心态上转变过去了,才能真正的引领技术的发展。
然而引领者是很难的,因为毕竟我们已经吃过了很多追随者的红利。比如说GPS美国人搞出来就是从无到有,但我们再跟着做,其实已经知道这东西是可以实现的了,大部分核心技术也都透明了,它就是一个工程实现的问题,难度跟从头研发出来完全不是一个数量级的。
我们的举国体制其实很适合作为追随者,毕竟解决工程问题,只要投入人力物力就行了,这是我们的优势,所以我们不用担心美国人抢先研发出来一种技术,只要他们研究出来了,我们知道是可行的,慢慢捣鼓总是能搞出来的。
从无到有的研发会花费大量的时间精力,经历各种各样的失败,而且还需要各种的机遇和灵感,不是简单地堆人力就可以出效果的。况且它还需要人敢于去想,敢于去尝试,敢于去干,这并不是太符合我们整个民族的性格。
但历史已经发展到今天这一地步,从人才储备以及整个历史趋势来看,我们的崛起和美国的衰落都是已经在不断地发生当中了,也许有一天美利坚不再引领人类技术进步,这个担子就不可避免的落到我们身上,我们要为此做好准备。
实际上我们需要更主动的去尝试作为引领者,首先的转变要在心态上,当我们决定做引领者的时候,就会从技术引领者的角度来看各种问题,去做各种尝试。我们站立的角度和心态,就决定了我们做事的想法和方式。先从心态上进行转变,剩下的文化和积淀,随着时间慢慢地积累,一步一步都会得到改善。
这些改善和进步又从另一方面能够更好地去影响我们的心态和自信,这就是一个正向的循环。我们现在正在外围不断地向这个圈子的内部靠近,现在可能觉得有点困难和不知所措,但我们走的越近就会觉得越舒服,越来越能找到感觉。